什么是Latency
延迟是指一个操作发生所需的时间。这意味着每个操作都有自己的延迟——如果有 100 万个操作,就会有 100 万个延迟。因此,延迟不能按工作单元/时间来衡量。我们感兴趣的是延迟的行为。为了有效地描述延迟,必须描述延迟的完整分布。延迟几乎从来不遵循正态、高斯或泊松分布,因此查看平均值、中位数甚至标准差是没有用的。
延迟往往是多模态的,这部分是由于响应时间的“间歇性卡顿”。间歇性卡顿类似于周期性的冻结,可能由多种原因引起,例如:垃圾回收暂停、虚拟机暂停、上下文切换、中断、数据库重索引、缓冲区刷新到磁盘等。这些间歇性卡顿从来不会遵循正态分布,并且模式之间的转换通常是快速而异质的。
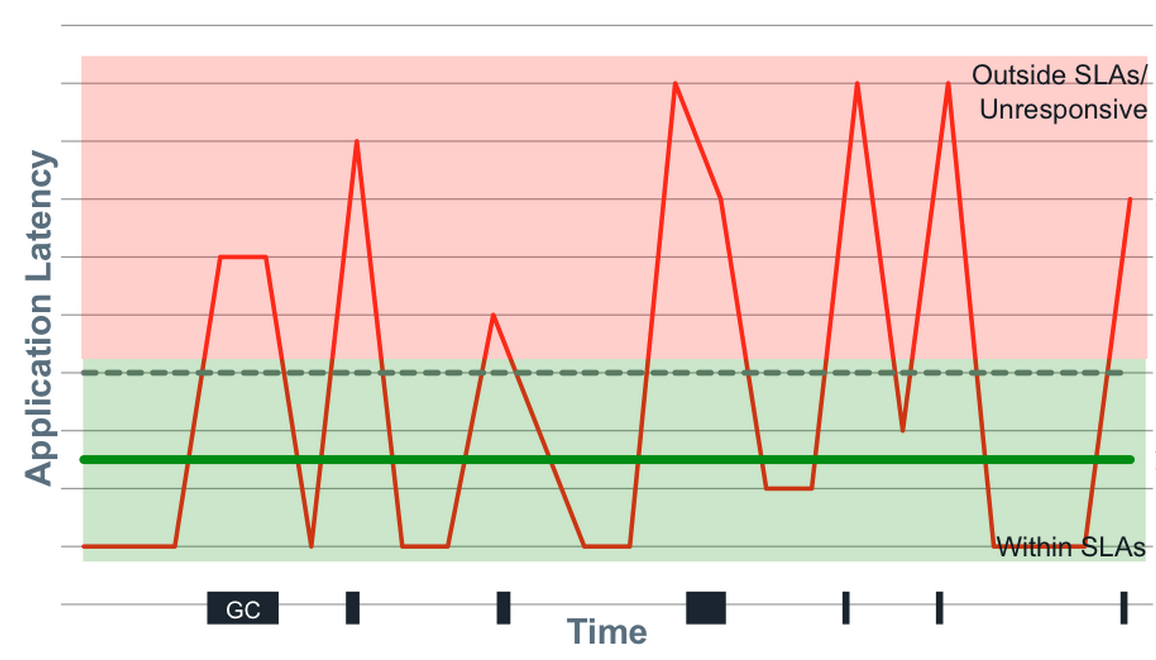
如何有效地描述延迟分布?必须看分位数,但这还不止于此。许多人会陷入一个陷阱,就是只关注“常见情况”。问题是,延迟行为比常见情况复杂得多。不仅如此,你认为的“常见”情况可能没有那么常见。
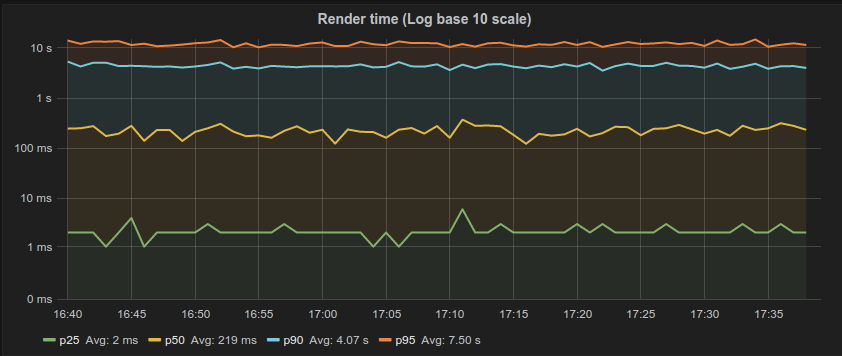
这部分是工具的原因。我们使用的许多工具不能很好地捕获和表示这些数据。例如,Grafana生成的大多数延迟图表(如下面的图表)基本上是没有用的。我们喜欢看漂亮的图表,通过绘制方便的图表,我们可以得到一个很有可读性的彩色图表。只看第95个百分位数是当你想隐藏所有不好的东西时才会做的事情。正如Gil所描述的,这是一个“营销系统”。无论是CTO、潜在客户还是工程师,总会有人上当。此外,平均分位数在数学上是荒谬的。为了节省空间,我们经常保留摘要并丢弃数据,但“第95个百分位数的平均值”是没有意义的。你不能平均分位数,但请注意你大多数Grafana图表中的标签。不幸的是,情况只会变得更糟。
Gil 说:“你永远不应该删除的最重要的指标是最大值。这不是噪音,这是信号。其余的都是噪音。” 对此,研讨会中有人自然地回应道:“但是如果最大值只是一个 VM 重启?这不能描述系统的行为。这只是一个不幸的、不太可能发生的事件。” 忽略最大值,你就等于说“这不会发生”。如果你能将原因识别为噪音,那你就没问题了,但如果你没有捕获这些数据,你就不知道实际发生了什么。
https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/